

1.范围
本部分规定了SD储量计算法(简称SD法)资源储量估算的基本原理、适用条件、基本要求、估算参数选择、估算操作流程、资源储量分类、SD法计算结果、自检、SD精度的应用等基本内容和要求。
本部分适用于运用SD法对固体矿产地质勘查和开发利用中的资源储量估算。
2.规范性引用文件
下列文件对于本标准的应用是必不可少的。凡是注日期的引用文件,仅注日期的版本适用于本文件。凡是不注日期的引用文件,其最新版本(包括所有的修改单)适用于本文件。
GB/T 12719 矿区水文地质工程地质勘探规范
GB/T 13908 固体矿产地质勘查规范总则
GB/T 17766 固体矿产资源/储量分类
GB/T 25283 矿产资源综合勘查评价规范
GB/T 33444 固体矿产勘查工作规范
DZ/T 0078 固体矿产勘查原始地质编录规程
DZ/T 0079 固体矿产勘查地质资料综合整理、综合研究要求
DZ/T 0130 地质矿产实验室测试质量管理规范
DZ/T 0227 地质岩心钻探规程
DZ/T 18341 地质矿产勘查测量规范
下列术语和定义适用于本文件。
3.1 SD动态分数维 SD Dynamic Fractional Dimension
是用分数维定量描述矿体形态复杂程度的一个量,它随着勘查程度的工程数变化在[0,1]区间内动态改变,用D表示。
3.2 矿体复杂度 Ore Body Complexity
3.2.1 是指在SD分数维的基础上,用以最终定量描述矿体地质变量复杂程度的一个特征量,用T表示。矿体复杂度分为:品位复杂度、厚度复杂度和综合复杂度。分别用Tc、Th、Tz表示。
3.2.2 矿体复杂度T 的表述式为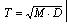 。M是对D的修正系数,称为变化度。变化度包括厚度变化度系数(用Mh表示)和品位变化度系数(用Mc表示)。
。M是对D的修正系数,称为变化度。变化度包括厚度变化度系数(用Mh表示)和品位变化度系数(用Mc表示)。
3.3 SD样条函数 SD Spline Function
用于矿产资源储量计算的一种样条函数,是SD法用矿体复杂度T对分段连续的三次样条函数经过系数修正的一个函数。
3.4 SD权尺 SD Weighting
SD权尺是根据地质变量在不同位置空间的作用大小来分配地质变量“权”的大小尺度。用于衡量相邻变量对主地质变量的影响程度并对地质变量进行修匀处理,获得稳健的结构地质变量。
3.5 结构地质变量 Geological Variable of Structure
指采用风暴值处理、权尺稳健、SD样条函数拟合等一系列数学方法排除随机因素的干扰,专门反映某种地质特征的空间结构及其规律性变化的地质变量。该结构地质变量具有相对性和可变性,在一定空间范围内相互影响,既与其所在的空间位置有关,也与周围的地质变量大小和距离有关。
3.6 框块 Blocks
是指SD法计算矿产资源储量时,按一定尺度对矿体进行划分,形成的基本块体。
3.7 风暴品位 Storm Grade
指SD法规定的在某一矿体中,在SD样条曲线上出现峰值,明显高于周边样品品位的孤峰值。
3.8 风暴厚度 Storm Thickness
指SD法中规定的在某一矿体中,单工程矿体厚度明显高于周围工程的矿体厚度值,其厚度在SD样条曲线上出现突出孤峰的矿体厚度。
3.9 框棱 Edge
是SD法特有的对工程控制程度进行量化的指标。用于衡量工程平均控制间距,其数值为平均线距和平均点距乘积开方值。
3.10 SD基距 SD Basal Scope Edge
是当工程控制程度可以求取真量时的最小控制间距,也是确认矿体接近矿体真态时的最小框棱,用Ha表示。
3.11 SD精度 SD Accuracy
是综合反映工程控制程度和资源储量精确程度的一个定量尺度,用η表示。是预测工程数、确定工程间距(框棱)、定量描述资源储量可靠程度、量化探采风险及定量划分勘查程度的依据。
3.12 SD靶区 SD Range
指在当前工程控制程度下估算的资源储量相对于资源储量真量的上下限范围,亦即推知资源储量风险的范围。
3.13 SD计算单元 SD Calculation Domain
是依据矿带(矿层)、矿体、矿石类型、勘查阶段、开采方式、矿体产状、构造破坏情况等对矿床的地质认识而具体划分的,用于矿产资源储量计算的某一次计算的范围,可以是单个矿体范围,也可以是多矿体范围,还可以是整个矿区范围。
3.14 SD断面线 SD Section Line
指在计算单元内用于SD法资源储量计算以及精度计算的断面投影线。主要是勘查线及少量根据实际情况设置的必要的辅助断面线(控制线)。
3.15 SD计算点 SD Calculation Point
指采用SD法计算时所划分计算单元内,参与计算的实际工程点(有矿工程、矿化工程及无矿工程)和辅助计算点(控制点和外推点)的总称。
4.基本原理
4.1 “SD动态分维拓扑学”也称为“地质分维拓扑学”是SD法的基本原理。是以构建结构地质变量为基础,运用SD动态分维拓扑学技术和SD样条函数工具,采用包括“降维(拓扑)形变”、“权尺稳健”、“搜索(积分)求解”和“递进逼近”等四大原理和SD稳健公式、结构地质变量公式、SD边值公式、SD复杂度公式、SD风暴品位下限值公式、SD样条函数公式、SD体积公式、SD精度公式等八组公式,预测资源储量精度,确定靶区,求取矿产资源储量。SD法的基本原理是有别于传统简单几何学原理和概率统计数学原理的,属于动态分维拓扑学范畴。
4.2 SD法通过一系列数学方法、技术、系统软件,求得准确可靠的资源储量及其精度
a) 通过建立SD动态分维理论对矿体(品位、厚度等)复杂程度进行定量、精细地描述;
b) 通过权尺稳健、风暴品位及厚度处理、齐底拓扑形变后建立SD样条函数等技术手段构建结构地质变量,将原始地质变量数据构建为具有规律性、代表性的稳健化数据;
c) 通过搜索积分求解计算出各框块的资源储量结果(体积、矿石量、金属量、品位等);
d) 通过递进逼近方法求得资源储量的SD精度,用SD精度来定量确定各矿块(框块)的资源储量地质可靠程度,同时确定出资源储量的风险靶区,预测达到某一勘查程度所需的工程数和框棱。
e) SD法的详细原理参见附录A。
5. SD法适用条件
SD法的应用与勘查阶段无关,适用于具有两个及以上工程(槽、井、坑、钻等)的数据,两条以上的剖面范围即可进行资源储量和SD精度的估算,获得资源储量的数量及精确程度成果。适用于固体矿产勘查、开采等各阶段、各种矿种、各种规模、不同成因类型条件下的各种矿床的资源储量估算。
6.基本要求
6.1 遵循SD方法的一般原则和要求,并采用相应的软件系统来完成资源储量估算。
6.2 根据矿床实际情况按矿种划分计算单元及计算方案类型。
6.3 各SD计算单元的断面线和计算点应根据具体控矿情况和计算要求确定。
6.4 应按照SD法的原则和要求,认识和使用SD法的资源储量靶区。
6.5 资源储量估算的过程和结果应符合客观真实性原则,所采用的文、图、表内容的协调一致。
6.6 资源储量估算过程中如有需要特殊说明的问题应予以阐述。
7.估算参数选择
7.1 设置计算单元
7.1.1 设置及划分方式
分为手工划分和自动划分两种。手工划分计算单元的前提条件是要有较明确的矿体(带)划分认识,然后采用SD软件系统自动绘制的剖面底图解析矿体,或利用已有的矿体(带)认识模型手工进行计算单元的划分;自动划分是SD软件系统根据对已有数据进行处理分析后给出划分方案,通过人机交互实现矿体及计算单元的划分。在计算时应根据矿床情况,分别以平行断面资源储量估算或不平行断面资源储量估算,选择合适的划分方式。
7.1.2 设置计算单元的基本原则
一般根据矿带(体)、矿石类型、工程类型分布、开采方式、矿体产状、构造控制特点并结合估算的目的和需求划分计算单元,一般一个矿区可以划分成一个计算单元,也可以划分为多个计算单元。划分的具体要求和原则如下:
a) 一般需按矿体划分,不同的矿体划分为不同的计算单元;
b) 若同一矿体产状变化大时,一般应分段计算,划分为不同的计算单元;
c) 不同开采方式且工业指标不同时,应划分不同计算单元分别计算;
d) 不同矿石类型分采分选且工业指标不同时,应划分不同计算单元分别计算;
e) 对于不同选冶要求的矿石,开发时可以分采分选时,应划分不同计算单元分别计算;
f) 当矿区内矿体对应连接较困难,多解性大,且品位变化较小时,允许按照矿带(即:不划分具体的矿体)划分计算单元;
g) 每一个计算单元都需命名,该名称称为计算单元名。同一矿区内的计算单元名不允许相同;
h) 构成计算单元的要素是断面线和计算点。具体需按本规程7.2、7.3规定合理设置断面线和计算点。
7.2 断面线参数设置
7.2.1 对计算单元内控制矿体的实际工程分布情况,确定勘探线的类型(平行或不平行或扇形等)选定平行断面线还是不平行断面线方式估算资源储量。
7.2.2 当出现实际工程附近未设置实际勘探线的情况时(如图1 a),应在这些工程的集中部位设置辅助勘探线(如图1 b)。辅助勘探线名称可按一定命名原则命名。
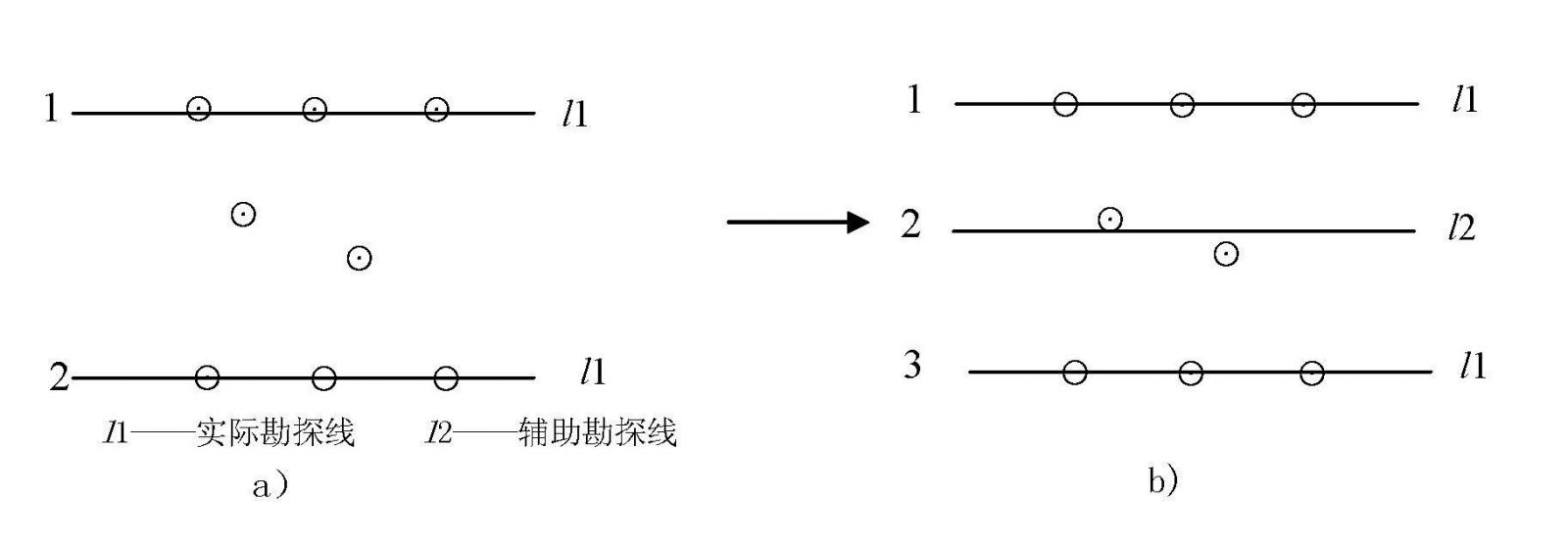
图1工程分布示意图
7.2.3 当计算单元内的计算对象为单孔或多孔单线控矿且矿体在走向两端均未圈边时,应在走向两端设置控制线(KZX)(如图2)。
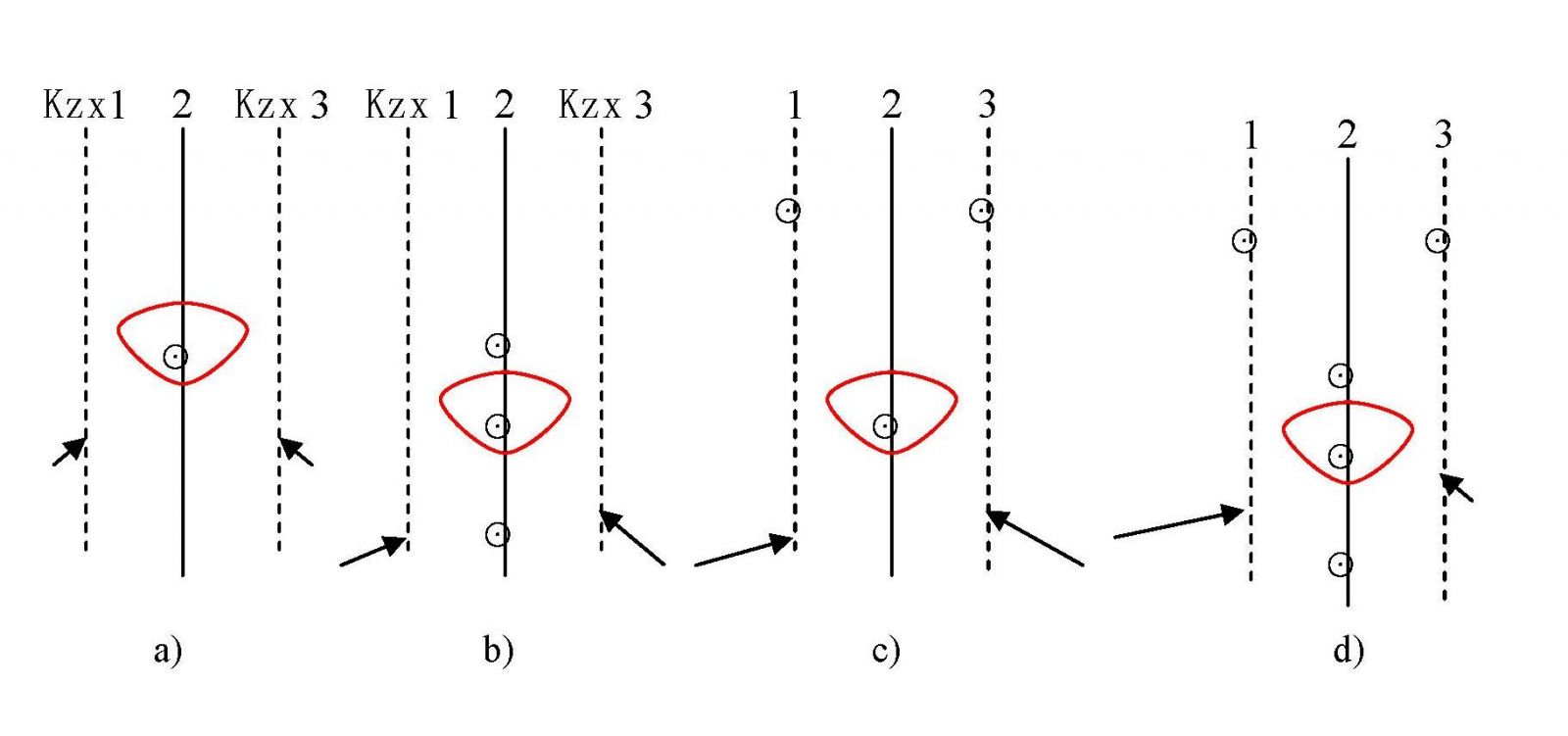
图2 控制线分布示意图
7.2.4 当矿体走向变化较大,变化较大部位又无实际工程控制者,应根据具体情况设置恰当的控制线(如图3)。如图3所示,根据2线和3线的工程揭露以及地表情况,在2~3线间仍然属于一条矿体,2~3线间矿体走向相对总体平均走向发生了急剧变化,为更加准确反映矿体各部位的展布形态,SD法估算时,需在变化较大部位(如:在2~3线之间)设置1条或多条控制线以准确控制矿体的实际形态,确保资源储量估算的准确性。
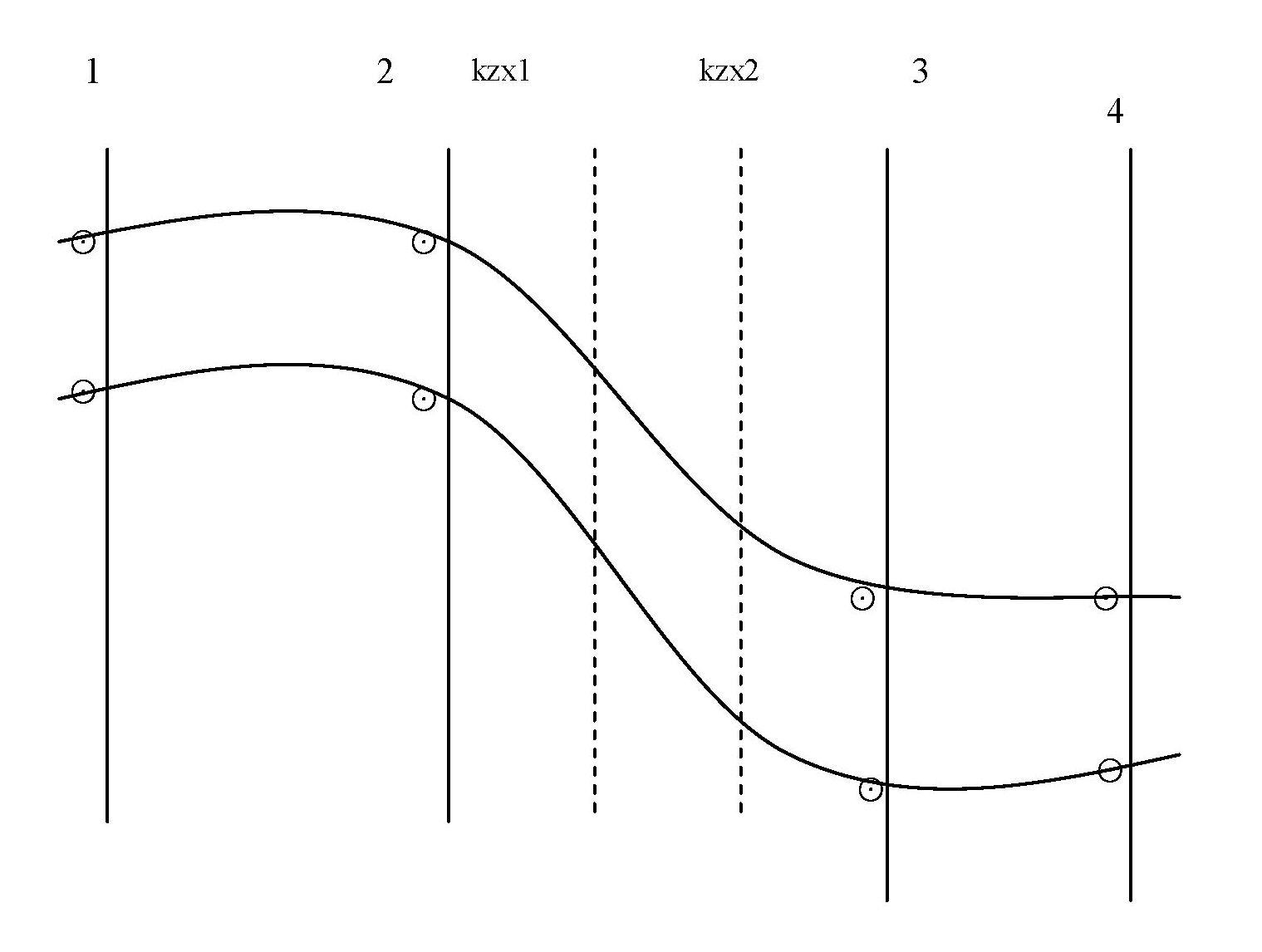
图3 水平投影示意图
7.2.5 当沿矿体走向方向存在岩体、断层等其他需要特殊控制的地质边界时,应在适当位置布置恰当的控制线。
7.2.6 当在两条以上已知断面线(勘查线或控制线)控矿基础上,沿着走向方向需作无限外推时,可在走向两端设置辅助线来控制计算的边界(如图4)。
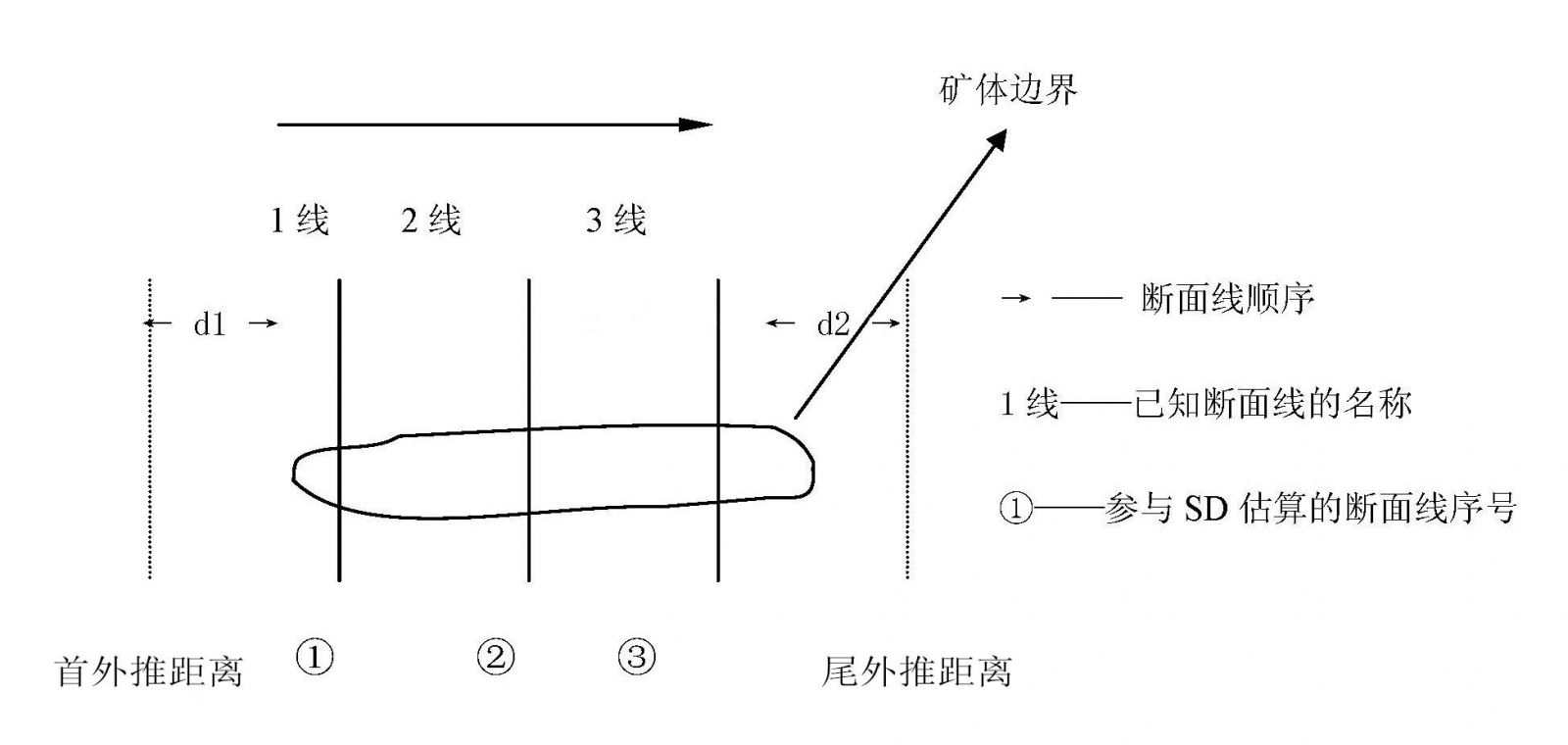
图4 辅助线示意图
7.2.7 一个计算单元最多有两条外推控制线,分别是首外控制线和尾外推控制线。外推控制线上没有实际工程,估算时不参与编号,但要提供其相关的信息,主要包括:外推控制线的性质、外推控制线数及外推距离。外推控制线与相邻断面线的距离,有首外推距离和尾外推距离之分,如图4,d1为首外推距离,d2为尾外推距离。
7.2.8 控制线名称一般以“KZX1”“KZX2”等依次命名的。控制线上无实际工程,但是其上要据实际地质认知设置控制点。
7.2.9 同一计算单元的各断面线首尾端方向需一致。
7.3 计算点参数设置
7.3.1 应首先选取计算单元内控制矿体的有效实际工程点作为计算点,如钻孔、探槽、坑道、浅井等。包括见矿点、矿化点、无矿点。
7.3.2 对于单孔控制的断面线需根据具体情况设置恰当的控制点KZD(如图5)。
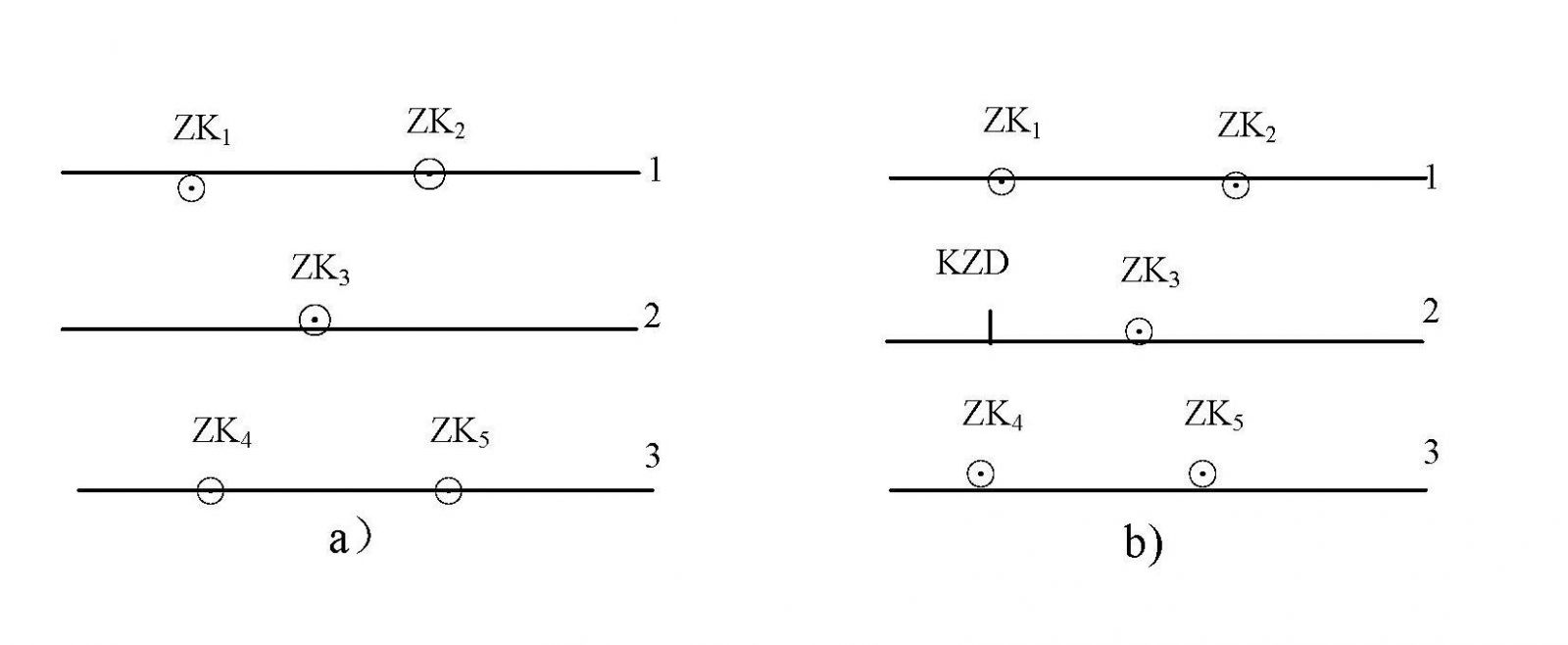
图5 控制点示意图
7.3.3 在无实际工程点的控制线上需根据具体情况恰当的设置两个控制点。
7.3.4 当断面线上有两个以上实际工程且矿体在端点两侧或一侧仍有延伸、且矿体的品位厚度变化主要以断面线方向为主时,可在端点两侧或一侧设置外推点。
7.3.5 控制点用“KZD”或“KZDJM(无矿控制点)”表示。
7.3.6 外推点用“WTD”表示。外推点分“首外推点”和“尾外推点”。外推点只需给定外推距离(指沿矿体延深方向的斜距),其品位、厚度是SD软件系统根据给定的位置采用SD 边值公式自动求得。
7.3.7 外推点与控制点同样作为计算边界点使用。
a) 外推点一定是设置在非单孔线勘探线实际见矿工程端点之外控制计算矿体的边界点。
b) 控制点既可在控制线上设置也可在实际勘探线上设置,可根据实际地质情况设置控制点距离。
c) 外推点受外推距离的限制,一般可参照几何法规范中工程间距确定或参考SD基距的倍数确定,外推适当距离。控制点则基本不受距离的影响。
d) 断面线边缘无矿工程之内控制边界只能设置控制点。
e) 断面线上仅一个工程时,不能设置外推点,只能设置控制点。
7.3.8 同一计算单元内计算点排序方向需一致。纵投影计算资源储量时断面线上计算点(工程点,辅助点)应按从高到底排序方式。
7.3.9 断面线上的计算点应以见矿中点位置进行就近归属。
7.4 SD计算方案类型参数确定
7.4.1 每一计算单元应分别确定各自的SD计算方案参数。
7.4.2 每一计算单元应分别对组成SD计算方案的 “计算类型”、“数据类型”、“定位系统”、“形质方案”四个基本参数进行单独确定;一般根据计算需求和原始数据提供情况确定。
7.4.3 计算类型分为“标准型”和“综合型”。当计算单元内工程有完备的原始样品数据和工程测斜数据时,采用原始样品分析数据作为基础数据进行计算时,均采用“标准型”。当计算单元内工程仅有单工程平均品位、厚度时,直接采用单工程的综合数据作为基础数据进行计算时,采用“综合型”。若需采用同样的单工程数据进行复核对比时,在验证其单工程合理的情况下,一般也采用“综合型”。
7.4.4 SD法应根据矿体的规模、产状、形态、勘查工程类型、工程对矿体的揭露情况不同,采用不同的计算类型进行。计算的数据类型分为A型、B型、C型、D型共四种。
7.4.4.1 A型数据适用于可划分多个台阶(中段)以及厚大(一般厚层~极厚层)、且分台阶(中段)估算的矿体。对于同源成因的矿带中品位厚度变化不大,但形态不规则,认知有多解性的矿体,也适用分层(段)估算选A型数据。选择A型的计算单元所利用的探矿工程可以是完全揭穿矿体的,也可以是未揭穿矿体顶底板的。若选择了A型,则必须对每一探矿工程揭穿矿体的属性进行标识。若数据类型选择了A型,则其计算类型必须选择标准型。用于计算的单工程计算厚度应是铅直厚度,积分计算的投影面是水平投影面或矿层(体)斜面。
7.4.4.2 B型数据适用于产状陡倾(一般倾角大于45°)的薄层矿体。选择B型数据的计算单元所利用的探矿工程一般要求揭穿矿体(矿带)的顶底板。若数据类型是B型、用于计算的单工程计算厚度应是水平厚度和真厚度,积分计算的投影面是垂直纵投影面。
7.4.4.3 C型数据适用于产状缓倾斜产出(一般倾角小于45°)的薄层矿体;选择C型的计算单元所利用的探矿工程一般要求揭穿矿体(矿带)的顶底板。若数据类型是C型、计算类型是综合型时,用于计算的单工程计算厚度应是铅直厚度和真厚度,积分计算的投影面是水平投影面或矿层(体)斜面。
7.4.4.4 D型数据适用于坑、钻结合施工,工程方向不一致时,不满足A、B、C型数据估算条件的情况。
7.4.5 定位系统包括地理坐标和相对坐标两种。这里的地理坐标指经过测量仪器准确测量的x、y、z三维直角坐标。相对坐标是指在估算范围内,按照SD法规定建立的相对直角坐标系(如图6、如图7)。

图6 A、C型相对坐标建立示意图

图7 B型相对坐标系建立示意图
如图6所示,A、C型数据相对坐标系是建立在水平投影面上,将平行于断面线的方向作为X轴方向,垂直断面线的方向作为Y轴方向,并且确定一个估算的基点坐标。
如图7所示, B型数据相对坐标系是建立在垂直纵投影面上,将平行于断面线的方向作为Z轴,垂直于断面线的方向作为Y轴方向,同样确定出一个计算的基点坐标。
7.4.6 形质方案包括框块、分块、A台阶、A框块、A分块。框块是在投影面上划分的若干个矩形条块。每个框块由沿断面线方向的条距和垂直断面线方向的块距构成。分块是在投影面上根据实际需求划分的任意计算范围。A框块、A分块都是在台阶的基础上进一步划分,B、C型一般选择框块计算,A型一般A框块计算。框块的大小一般采取SD系统根据矿床具体情况自动确定的大小。特殊情况下,可根据用户的特殊需要进行适当调整。
7.4.7 由计算类型、数据类型、形质方案、定位系统四个基本应用参数联合构成的SD计算方案,常用的包括(关联关系见图8所示):
a) 标准型系列计算方案有:
1) 标准型A型地理坐标台阶、框块、分块
2) 标准型B型地理坐标框块、分块
3) 标准型C型地理坐标框块、分块
b) 综合型系列计算方案有:
1) 综合型B型地理坐标框块、分块
2) 综合型B型相对坐标框块、分块
3) 综合型C型地理坐标框块、分块
4) 综合型C型相对坐标框块、分块
5) 综合D型地理、相对坐标框块、分块
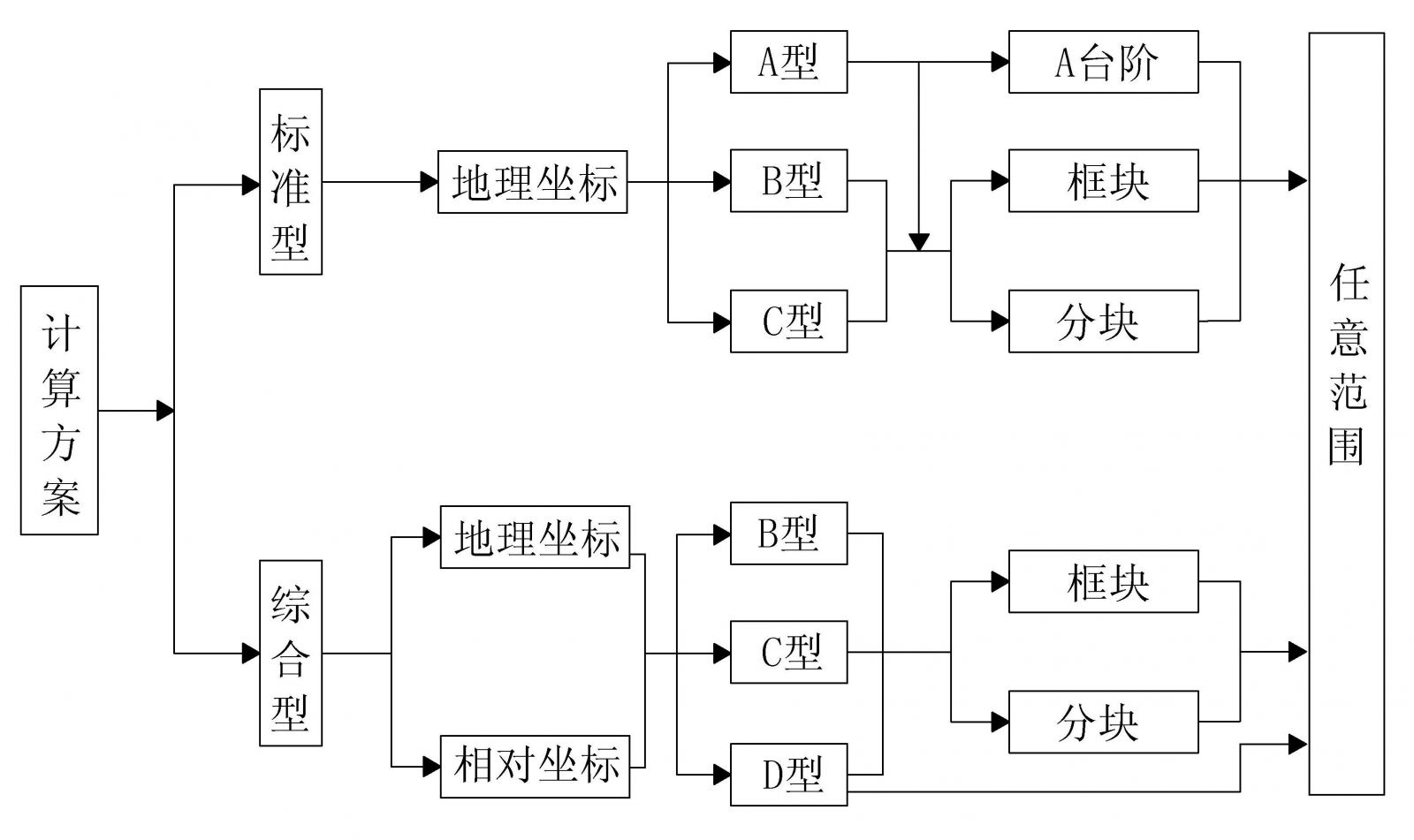
图8 SD法计算类型、数据类型、坐标系统、形质方案关联示意图
7.4.8 矿体规模参数确定
a) 矿体规模分为特大型、大型、中型、小型、微型。大中小型一般参照各矿种的勘查规范确定,特大型一般为大型的2倍以上,微型(特小型)一般为小型的1/2以下。
b) 矿体规模应按计算单元单独确定。
c) 确定矿体规模时,特殊情况下应考虑初步估算的资源储量结果进行适当调整。
7.4.9 矿床成因类型参数确定
a) 矿床成因类型按内生、外生和次生,分为九大类,分别为沉积矿床、沉积(变质)矿床、层控矿床、斑岩型矿床、热液型矿床、岩浆岩型矿床、矽卡岩型矿床、残坡积矿床、砂矿床。具体根据矿床具体情况合理确定。
b) 矿床成因类型按计算单元单独确定。
c) 矿床若有多种成因类型时,应按主要的成因类型确定。
7.4.10 无限外推范围参数的确定
SD法根据SD样条曲线按照矿体品位厚度的变化规律搜索有限外推边界;对于无限外推边界,一般依据SD法通过精度法自动计算的基距以及相应地质可靠程度所对应的框棱来确定。
7.5 矿体产状方式参数选择
7.5.1 一般可由SD软件系统自动根据圈矿后的单工程数据求取各工程的矿体产状。
7.5.2 当计算单元中所利用的工程出现不能完全揭露矿体顶底板或其他特殊情况,自动求取的单工程数据不能作为矿体产状计算的基础数据。不能完全合理地反映矿体产状时,应根据矿床实际情况直接给定合理的矿体产状。当整个计算单元的矿体产状变化不大时,可直接给定统一的产状;当矿体在不同部位产状变化较大时,应根据具体情况按照不同断面或不同工程给定矿体产状。
7.6 体积质量求取方式参数确定
7.6.1 体积质量即矿石体重,计算时首先应考虑湿度校正,一般当湿度>3%时应进行湿度校正。SD法主要有四种体积质量求取方式,分别是平均体积质量式、品位回归方程式、样品自然岩性式、品位等级区间式。估算时应根据矿床具体情况合理选择。
7.6.2 矿石体积质量应针对每个计算单元单独确定。
7.6.3 平均体积质量式是将矿区所有小体积质量样采用算术平均法计算出平均体积质量值后,利用此平均体积质量进行估算,是最常见的一种体积质量求取方式。体积质量变化一般比品位变化小得多,故体积质量样品的采取数量也较少。如果所计算的矿床的控制程度较低,一般用算术平均法计算的平均体积质量即可保证资源量计算精度要求;因此,平均体积质量是适用于矿床不同部位体积质量变化不大或勘查程度精度要求不高时使用。
7.6.4 品位回归方程式是每个见矿样的体积质量与一个或多个矿种的组合品位建立的一种回归模型,以此求出每个样的体积质量,进而求出每个工程乃至每个框块的体积质量。品位回归方程式适用于矿种组分较多、品位或品位的组合对体积质量的相关性较大的矿床,常用的有铅锌矿床等。
7.6.5 样品自然岩性式是指样品的体积质量受岩性影响较大的情况。当同一矿床不同岩性或不同矿石自然类型的体积质量相差较大时,应采用样品自然岩性式单独求取体积质量。
7.6.6 品位等级区间式主要是针对单一矿种的品位区间段与体积质量关系密切的情况。常用于铁矿等黑色金属矿产。
7.7 地质可靠程度区间参数确定
确定地质可靠程度等级参数是由SD软件提供SD精度来具体确定。用SD精度确定的具体地质可靠程度等级区间分别为:
SD精度为 80% ≤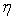 ≤ 100 % 表示地质可靠程度是探明的;
≤ 100 % 表示地质可靠程度是探明的;
SD精度为 45% ≤< 65 % 表示地质可靠程度是控制的;
SD精度为 15% ≤< 30 % 表示地质可靠程度是推断的;
SD精度为 2% ≤< 10 % 表示地质可靠程度是预测的。
除以上四个等级区间外,其余区间为相应的待定区间:
SD精度为 65 %≤<80 % 表示地质可靠程度是探明控制待定;
SD精度为 30 %≤<45% 表示地质可靠程度是控制推断待定;
SD精度为 10 %≤<15% 表示地质可靠程度是推断预测待定;
SD精度为 0 %≤< 2% 表示地质可靠程度是无意义的。
待定区间不属于地质可靠程度等级区间,它应结合地质研究程度,给予相应的等级确定。SD法精度对地质可靠程度的定量划分标准中,对于处于待定区间的地质可靠程度通过SD地质可靠程度待定区间归属专家系统进一步定量确定。
7.8 待定区间专家系统参数确定
7.8.1 该专家系统充分考虑了工程控制程度。矿体变化规律,以及水文地质、工程、环境、构造等综合因素。具体归属参数包括:勘查阶段、矿体形态、构造、水文地质、工程、环境、类比条件,矿体复杂度。
7.8.2 确定地质可靠程度待定区间归属参考标准
a) 矿体形态:
1) 简 单:厚层状,层状,大脉状。
2) 较简单:似层状,薄层状,单脉状。
3) 一 般:分叉式似层状,透镜状,层式脉状。
4) 较复杂:不规则状。
5) 极复杂:极不规则状,囊状,鸡窝状。
b) 矿体构造及内部结构:
1) 简 单:产状变化小,无大的断层破坏,节理裂隙不发育,无或极少夹石层。矿体边界清晰,内部组分均匀。
2) 较简单:产状变化较小,有断层,但破坏性小,有明显节理有较少夹石层。或矿体边界不清晰,内部组分不均匀。
3) 一 般:产状有波状起伏,有部分矿体被断层破坏,节理发育,裂隙明显,有夹石层。
4) 较复杂:产状变化较大,或矿体被多组断层错开,或有厚薄不等的多层夹石层。矿体小,变化大。内部组分不均匀。
5) 极复杂:产状变化大,(矿体倾向、走向、陡缓变化很大),或多组断层严重破坏矿体的完整性,或多层不连续夹石层。矿体小而多不连续。内部组分极不均匀。
c) 水文地质:
1) 简 单:矿体位于当地侵蚀基准面上,地形有利于自然排水,地表水不易形成水体。
2) 较简单:矿体大部分位于侵蚀基准面以下,但近岩层无含水层或近岩有含水层,但有隔水层隔开,地表水不形成水体。
3) 一 般:矿体位于侵蚀基准面以下,含水层对矿山生产不造成大的危害。
4) 较复杂:矿体位于侵蚀基准面以下,临近岩体有富水层,或地表水形成水体,矿山开采时易形成较大漏水量。
5) 极复杂:矿体位于侵蚀基准面以下,临近岩体有富水层,或裂隙水或岩溶发育,地表水亦形成水体,易使矿山形成大的漏水量。
d) 工程地质:
1) 简 单:矿体围岩单一,矿体力学强度高,节理、裂隙不发育,稳定性好;
2) 较简单:矿体围岩较单一,矿体力学性能较强,矿体节理裂隙较多;
3) 一 般:矿体力学性能一般,可能有较强风化性,节理、裂隙较发育;
4) 较复杂:矿体风化强,或者节理、裂隙很发育;
5) 极复杂:矿体遭强烈风化,或者遭构造破坏,形成破碎矿带。
e) 环境地质:
1) 简 单:无原生环境地质问题,矿石及废弃物不易分解出有害组分,采矿活动不形成对附近环境和水体的污染。
2) 较简单:一般情况下,采矿活动中,不易对环境形成污染,不会出现有害组分。
3) 一 般:环境地质情况不明、矿石及废弃物不易分解出有害组分以及采矿活动是否对附近环境和水体污染的情况不明。
4) 较复杂:存在原生环境地质问题,或矿石及废弃物可能分解出有害组分,或采矿活动可能对附近环境和水体污染。
5) 极复杂:严重存在原生环境地质污染,或采矿活动中不可避免存在对环境的严重污染。
b) 类比条件:
1) 简 单:本地区有可类比的已确知的矿体,其形态、构造、矿化、水文及工程地质为“简单”者;
2) 较简单:本地区有可类比的已确知的矿体,其形态、构造、矿化程度“简单”,水文及工程地质为“较简单”者;
3) 一 般:本地区有可类比的已确知的矿体,为“较简单”者;或无类比的,已知此矿形态、构造、水文地质或工程地质“简单”者;
4) 较复杂:本地区有可类比的已确知的矿体,为“一般”者;或无类比的,已知此矿形态、构造、水文地质或工程地质“一般”者;
5) 极复杂:本地区有可类比的已确知的矿体,为“较复杂”者;或无类比的,已知此矿形态、构造、水文地质或工程地质“较复杂”者。
7.9 可行性参数确定
不同勘查阶段,可行性研究程度要求不同。根据矿区(床)实际情况,确定“可行性研究参数”,主要包括“概略研究”、“预可行性研究”、“可行性研究”。
7.10 经济参数确定
确定经济参数方式有三种:定性式、品位区间定量式、效益品位定量式。
7.10.1 定性式
当可行性研究阶段为“概略研究”时,则整个矿段的经济意义只能定性确定为“内蕴经济的”。
7.10.2 品位区间定量式:
a) 先由用户自定义主矿种的品位区间,然后系统据此定量确定各块段的经济意义,不同部位其经济意义不同。
b) 用户可以根据可行性论证或开采经济评价结果,直接录入各经济意义级别的品位区间。一般情况下,常以工业指标为依据。如:
1) 块段品位大于或等于最低工业品位者,确定为经济的;
2) 介于最低工业品位与边界品位之间者,确定为边际经济的;
3) 小于边界品位者,确定为“次边际经济的”;
c) 该方式主要用于详查及以上阶段且进行了预可行性研究(或可行性研究)的金属矿床和部分非金属矿床。
7.10.3 效益品位定量式:
a) 主要以“内部收益率”作为衡量不同地质可靠程度的矿产资源储量经济意义的定量指标。
b) 内部收益率是评价矿床在估算期内各年净现金流量现值累计等于零时的折现率,它反映其内部获利的水平。经可行性研究或预可行性研究得出的内部收益率,当大于或等于行业基准内部收益率是经济的;在零至行业基准内部收益率之间的,即接近盈亏边界的,是属于边际经济的;小于零的是次边际经济的。
c) 选用该方式时,要求首先确定矿床(区)、经济评价相关指标,如:年生产规模、采选回收率、产品售出价格、采选总成本等,然后系统求取内部收益率后自动确定出各个框块的经济意义。
8.资源储量估算操作流程
8.1 应用步骤综述
8.1.1 SD法估算过程一般分为三个阶段八个步骤(见图9)。第一个阶段为收集分析原始资料,包括原始资料收集和原始资料分析两个工作步骤;第二个阶段为正式计算,包括组织SD法矿区勘查原始数据、矿体(带)解析、形成SD计算单元数据、确定估算参数、运用SD软件进行估算;第三阶段为成果提取,包括生成和分析提取所需的成果文字、附图、附表等八个工作步骤。

图9 SD法应用步骤示意图
8.1.2 计算时,若矿区矿体比较简单或已经有成型的对矿体认知的资料,可略去第三、第四步的工作,直接从第五步手工组织SD计算单元开始。
8.2 原始资料收集
原始资料的收集按照现行相关规定执行,对于已经形成的历史资料,应尽量核查其真实性。
8.3 分析及组织数据
各类原始数据的分析与组织均与现行相关规范一致。仅在资源储量计算时,将原始数据按照SD方法及软件系统规定的数据格式填写即可。
8.4 矿体(带)解析
8.4.1 矿体解析的方式有软件自动矿体解析和人工矿体解析两种,根据矿床实际情况合理选择。对于厚大矿体,矿化均匀而且较富的矿体,则一般由软件自动矿体解析结合人机对话完成。在解析的过程中,对矿体的圈定既可采用单指标方案也可采用多指标方案圈定,而对于薄层且复杂矿体宜采用多指标方案圈定。若矿体简单,不需严格地圈出矿体的形状即可判定矿体的对应关系,则只需要给出矿体赋存的区域即可。也可初步确定工程间矿体对应关系,直接由人工参照现行规范进行解析,交互调整并最终圈定矿体。
8.4.2 SD法根据已认知的地质规律,采用多指标圈矿,是采用常用指标体系中的边界品位及边界品位与矿化品位之间的品位值,圈出的一个比较完整的矿化区域,根据矿体复杂度和基距等指标,采用常用指标体系中的边界品位和最小可采厚度搜索出框块内的矿域和非矿域,然后再用常用指标体系中的工业品位和最小可采厚度判别出工业矿框块和低品位矿框块,根据SD精度定量确定框块资源储量类型,最后分别统计相应的资源储量。
8.5 形成SD计算单元数据
8.5.1 按本规程前述原则,合理划分计算单元并确定各计算单元的计算方案类型。按照各计算方案的要求组织相应的计算单元数据。
8.5.2 计算单元数据有自动生成和手工组织两种方式。自动生成方式是通过自动解析矿体的过程来自动完成;手工组织是根据矿体解析成果按照SD法及其软件系统SD计算单元数据要求组织。
8.5.3 若已组织了SD矿区数据,则此时仅需在SD矿区数据表的基础上进行完善,主要完善的数据是样品数据中的矿体号(若按矿体划分计算)、各计算单元基本情况、基岩界线数据和投影地形点数据(矿体露头或接近地表时)等。投影基岩界线数据一般包括投影基岩界线点序号、线序号、距离、标高、矿体号等;投影地形点数据一般包括投影地形点序号、线序号、距离、标高、矿体号等。
8.5.4 采用综合型计算,则工程数据需要按照工程的矿中点坐标、单工程品位及厚度值组织。
8.5.5 若采用A型数据计算,则应补充台阶数据的内容,一般包括台阶划分方式、台阶数、台阶序号、台阶间距等。
8.6 确定基本估算参数
按照本规程9.1,9.2,9.3的原则和要求确定各估算参数。
8.7 获取过程参数
8.7.1 计算时,采用SD软件系统进行资源储量估算,按照SD法软件操作要求进行操作。主要步骤是接收和转换SD计算单元原始数据、计算参数设置、数据检验、计算、审定。
8.7.2 矿体复杂度由软件系统根据SD动态分维法自动求得,是矿体复杂程度的最终衡量参数,分品位复杂度Tc和厚度复杂度Th以及矿体的综合复杂度Tz。矿体复杂度值在[0,1]之间,按照五级定量划分标准判别其复杂程度。具体求取公式及划分标准,参见附录A。
8.7.3 风暴品位的识别和处理是由SD软件系统在计算过程中根据倍数限与矿体复杂度的相关关系采用定量公式自动处理,定量计算求得,最终用风暴品位下限值替代风暴品位参与计算。具体求取过程参见附录A。
8.7.4 风暴厚度是由SD软件系统在计算过程中自动识别和处理。
8.7.5 单工程品位、单工程厚度由SD软件系统自动求取。
8.7.6 矿体断面面积、框块体积、框块平均品位、矿石量、金属量等均由SD软件系统依据工业指标搜索,通过SD样条函数积分自动计算求得。具体求取过程参见附录A。
8.7.7 外推范围内品位厚度搜索,是外推范围内的矿体厚度和品位按照SD样条函数搜索确定,一般遵循矿体变化规律,进行曲线外推,是非等值外推,即:外推范围内各处的品位和厚度不同。有限外推范围内品位厚度一般小于见矿工程,无限外推范围内品位厚度可能大于相邻见矿工程,也可能小于相邻见矿工程。
9.资源储量分类
9.1 地质可靠程度确定
地质可靠程度由SD精度自动定量确定为“探明的”、“控制的”、“推断的”、“预测的”。具体确定参数详见本规程7.7和7.8。
9.2 可行性研究确定
不同勘查阶段,可行性研究程度要求不同。根据矿区实际情况,确定“可行性研究参数”,主要包括“概略研究”、“预可行性研究”、“可行性研究”。具体确定参数详见本规程7.9。
9.3 经济意义确定
经济意义参数确定方式有三种:“定性式”、“品位区间定量式”、“效益品位定量式”。具体确定参数详见本规程7.10。
9.4 资源量和储量类型划分
9.4.1 资源量类型划分
运用SD系统进行资源储量估算,系统自动确定地质可靠程度等级,按照地质可靠程度由低到高,资源量分为推断资源量、控制资源量和探明资源量。
9.4.2 储量类型划分
按照技术可行性和经济合理性结果及地质可靠程度由低到高,储量分为可信储量和证实储量。
10.SD法计算结果
10.1 计算结果
10.1.1 报告结果
SD法计算的结果,除最佳估值外,还提出资源储量靶区,它由估值的高值和低值组成了资源储量的区间。它是通过SD精度自动求取。具体求取过程参见附录A。结果主要包括资源储量估算原始数据表、资源储量估算参数表、结果数据表(圈矿信息表、工程控制程度预测表、资源储量结果表、资源储量靶区表等),详见附录C。
10.1.2 图件结果
SD系统根据矿区数据,自动生成和编制相应图件。主要包括资源储量分类图、品位品级分划图、地形地质图、剖面图、钻孔柱状图等图件。
10.2 采空区或压覆范围
当有采空区或有压覆时,一般先估算累计查明资源储量,然后以此为基础,扣除保有资源储量求得消耗资源储量;或者扣除消耗资源储量求得保有资源储量。这些结果的统计均由软件协助完成。
11.估算结果自检
SD法目前常采用SD标准型框块搜索法估算,其估算结果的可靠性可用SD整体搜索法或综合型法结果进行互检。当二者靶区范围重合率达80%以上时认为框块法结果安全性、可靠性较高。若达不到此重合率要求则需进一步分析、调整框块的大小直至满足要求。
12.SD精度的应用
12.1 SD精度对勘查程度判别
SD精度对勘查程度的判别中,SD法提供矿体的总精度和各框块的资源储量精度两个数值。前者可用于定量判别达到的勘查程度级别。后者表示矿体各个部位的控制程度高低。
12.2 SD精度对地质可靠程度判别
SD精度对地质可靠程度的定量判别中,可直接定量确定各框块的地质可靠程度,为地质人员(或合资格人/胜任人)提供量化的标准和工具,避免完全靠经验性的定性判断而引发的诸多争议。
12.3 SD精度对工程数预测
SD精度不仅对资源储量估算结果精确程度进行确定,而且还对其勘查程度、地质可靠程度定量判断,并对勘查区进行勘查风险控制和对勘查工程数进行预测。工程数和框棱的预测是通过SD精度实现的,它是在当前工程控制程度下对未来达到任何勘查程度所需的工程数和框棱做出的预测判断。这种预测,是用于勘查设计、动态指导勘查进程,提高勘查过程中的可控性、计划性,避免盲目性和勘查风险的一个重要指标。
12.4 SD精度对风险靶区控制
SD精度对风险靶区的控制,是用SD法提供的资源储量靶区结果,以最佳估值乘除SD精度得到资源储量靶区的下限值和上限值,用于指示当前工程控制程度下,资源储量的变化区间,即资源储量风险范围,从而用此靶区进行有效地控制风险。用于较低勘查程度及存在较大资源储量风险的矿床和各种用途下资源储量风险的判别和控制。
13.资源储量变化情况评述
13.1 评述内容主要包括:在与以往报告相比时,重叠范围内资源储量变化原因一般有矿体形态认识变化(厚度变化,产状变化,甚至矿体对应关系变化,新增矿体变化等),矿石体积质量的变化,资源储量采矿消耗变化,不同方法的估算差异等几个方面的原因。
13.2 SD法与其他方法估算的主要差异有以下几个方面
a) 风暴品位处理差异;
b) 外推边界差异(特别是有限外推边界),外推范围内矿体厚度品位的求取方式差异(SD法为曲线非等值外推);
c) 资源储量的估算可不依赖人工划定的矿体形态进行估值;
d) 直接根据原始数据求得工程控制程度,不需要按照勘查类型进行估算;
e) 资源储量分类差异。除去其它因素外,主要是地质可靠程度的差异,SD法通过SD精度定量确定。
14.SD法资源储量报告的编写
14.1 总体要求
采用SD法估算资源储量的勘查、核实等各类报告,除矿体特征描述、勘查方法及工程布置、资源储量估算章节及相关附图附表与其它估算方法报告编制格式和内容要求有所不同外,其余章节安排及内容依从现行标准对报告的要求。
14.2 正文部分
14.2.1 矿体特征章节:在正文中,凡有关矿体厚度复杂程度、品位复杂程度的内容,应以SD复杂度及其所属的等级去衡量和描述,主要表现在矿体特征一节。矿体产状应结合SD法估算的产状综合描述。可使用SD软件绘制的矿体立体透视图描述矿体的空间关系。
14.2.2 勘查方法及工程布置章节:在此节中,有关工程间距合理性的评述,应采用由SD精度所确定的判别标准,用SD精度、框棱等去衡量、检验当前工程对矿体的控制程度,并评价工程间距布置的合理性。
14.2.3 资源储量估算章节:首先应描述所采用的工业指标,清楚说明具体要估算的对象和范围以及依据的原始资料来源(特别是采空区数据),对资料的有效性进行评述和说明。重点说明计算中各参数的选择依据,包括计算单元的划分,计算方案的确定,矿体规模、矿床成因、矿石体积质量、矿体产状、外推距离、框块大小等的设置依据,描述风暴品位处理的结果以及资源储量估算的最终结果(包括SD精度)、对下一步工作的预测成果,结果可靠性自检结论。
14.2.4 章节提纲和内容要求
具体章节提纲和内容要求详见附录B。
14.3 生成提取所需的成果附图、附表
利用软件系统生成附图、附表(附录C)。
SD法是以现代数学地质为基础的动态分维拓扑学理论的中国自主资源储量估算方法体系,有别于前苏联体系的传统简单几何学原理和欧美体系的概率统计数学原理,于20世纪末由我国地质科技工作者唐义和蓝运蓉在地质找矿、矿产资源勘查实践中运用数学与计算机为工具共同创立。SD法具有理论、原理、方法等方面的含义,分别代表“Spline”样条函数和“动”态分维;代表“搜”索、“递”进;代表“审定(即:对资源储量精确程度的定量确定)”。SD法体系主要分为SD储量计算法和储量审定法(SD精度),还包括四条原理(“降维形变原理”、“权尺稳健原理”、“搜索求解原理”和“递进逼近原理”)、八组公式(SD稳健公式、结构地质变量公式、SD边值公式、SD复杂度公式、SD风暴品位下限值公式、SD样条函数公式、SD体积公式、SD精度公式)及系列软件(单机版本、企业网络版本和现代移动互联网版本)。
A.1 定量确定矿体复杂度
为了能比较准确描述矿体的复杂程度,SD法引入了动态分维理论,并提出了品位复杂度和厚度复杂度的概念,这两个概念是适合矿体特性和要求,从动态分维角度来精细地刻画和描述矿体复杂程度。它充分考虑了地质变量的空间结构性特点,包括工程品位、厚度的大小,工程所处的位置及工程间的距离等。
矿体复杂度分品位复杂度Tc和厚度复杂度Th以及矿体的综合复杂度Tz,用以定量描述矿体的复杂程度。复杂度在[0,1]之间,是矿体复杂程度的最终衡量参数,具体表达通式如下:
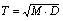 (1)
(1)
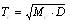 (2)
(2)
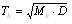 (3)
(3)
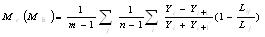 (4)
(4)
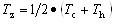 (5)
(5)
Tc——矿体品位复杂度;
Th——矿体厚度复杂度;
Tz——矿体综合复杂度及T;
Mc——品位变化度;
Mh——厚度变化度;
D ——SD分数维;
m ——线数。
j ——线的序号,j=1.2. … m;
n ——点数;
i ——观测点序号,i=1.2.… n;
Yi ——观测点的观测值(单工程的平均品位或厚度值);
Lij ——小区间距离: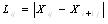 ;
;
Lj ——j线I个区间总距离: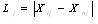 ;
;
SD法对矿体复杂度(厚度复杂度、品位复杂度、综合复杂度)按照复杂程度进行了五级定量划分标准,具体应用中均以此为标准:
a) 简 单: 0~0.0625
b) 较简单: 0.0625~0.25
c) 一 般: 0.25~0.39
d) 较复杂: 0.39~0.56
e) 极复杂: 0.56~1
A.2 风暴品位处理
风暴品位的存在是客观的,它的出现会影响平均品位的可靠性。SD法不去寻求原始数据的统计规律,而用稳健处理数据的方法,将原始数据处理成相对平滑的空间结构的数据,即结构地质变量,但是,SD法仍然要求结构数据的合理性即合理均值。为排除特异值对结果正确性干扰,SD法对它进行了稳健性处理。
SD法采用修匀数据的办法来消减风暴品位在参与计算时过大的影响力,从而达到计算结果稳健可靠的目的。SD法处理风暴品位值的办法是,将风暴品位值适度削减,将削减值替代风暴值,置于原始数据中参与计算。风暴品位处理具体公式:
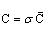 (6)
(6)
(6)式中:
C ——风暴品位下限值;
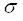 ——风暴品位倍数限;
——风暴品位倍数限;
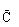 ——采用搜索法计算的矿体平均品位。
——采用搜索法计算的矿体平均品位。
风暴品位倍数限计算公式:
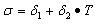 (7)
(7)